Committed Treatments
Overview
Committed treatments allow you to specify pre-committed treatments that have to be placed in your model before and other treatments are triggered. You can use committed treatments in both a Forecast Model and in a Treatment Selection Model.
Required Columns
The following columns are mandatory for the committed treatments data:
‘elem_index’ - The zero-based element index that identifies the element on which the treatment is to be placed. This index should map directly to the zero-based row that matches the element in your raw input data.
‘treatment’ - The name of the treatment type. This name should match exactly (assume case-sensitive) the name of one of the treatments in your Treatments Definition Data.
‘period_calendar’ - the calendar period in which the treatment is to be placed. The calendar period is the model period plus the model initialisation year. These values should always be greater than the model initialisation year, otherwise an error will be thrown to inform you of the problem.
‘treatment_qty’: the treatment quantity to match the unit rate specified in your Treatments Definition data.
‘treatment_comment’: A comment related to this treatment. The column is mandatory, but you can leave the values blank. However, it is recommended that you always leave some note here to indicate that this is a committed treatment. This will help you better understand and debug your model output.
‘treatment_reason’ - similar to ‘treatment_comment’ above - this is an optional value. You can leave it blank if you wish, but the column is mandatory.
Optional Columns
If you are reading committed treatments from an input file (as in the case of the Desktop Version of Cassandra), you can add additional columns to your committed treatments data. These columns may be helpful to ensure or check that you have assigned the correct element index values to each treatment (see note below).
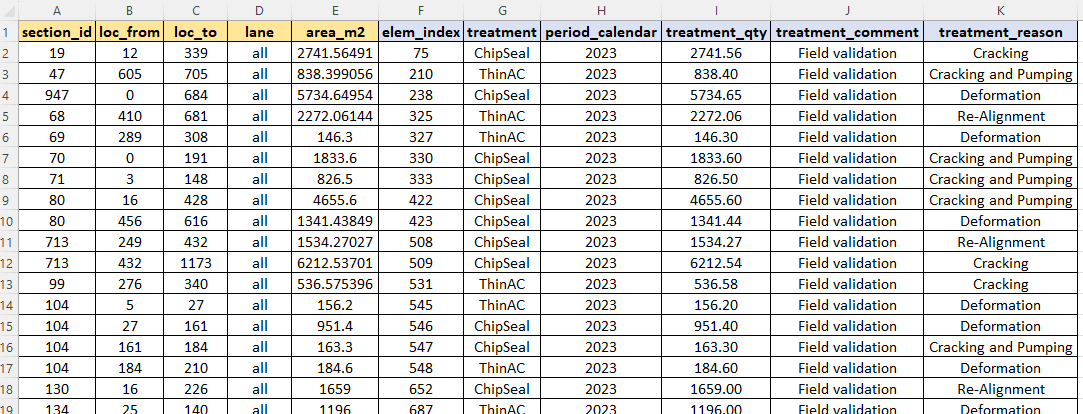
Example Table
In the example shown below, the mandatory columns are highlighted in blue while examples of optional columns are highlighted in yellow.
Cost Calculation
Committed treatments can be placed in any model period except period zero. That is, the committed treatments need to be placed in the first period or later. When committed treatments are imported, the base-year cost is automatically re-calculated using the specified treatment period, the treatment quantity, specified unit rate for the treatment type and discount and inflation rates.
The reason for doing this - as opposed to allowing you to explicitly specify a cost - is to ensure that the specified treatment quantities and unit rates are congruent in model outputs. For example, if you specify a cost for a committed treatment which is not the product of the quantity and the unit rate, this will cause discrepancies between your ‘known’ cost for committed treatments, and some of the reports that are calculated during post-processing. Also, this procedure allows Cassandra to consistently apply the same discount and inflation rate for discounting future costs to a base rate (year-zero cost). Again, this avoids situations where there are discrepancies between costs calculated internally during a model run, and costs that you pre-determine for committed treatments.
In some cases your committed treatment costs may not be a simple product of area and unit rate. For example - a cost may include some site establishment or extra-over costs that are incorporated into the project costs. In such cases, you simply need to calculate the ‘effective quantity’ that will yield the project costs when multiplied by the unit rate for the treatment. You should then enter this effective quantity into the ‘treatment_qty’ field as defined above.
Assigning Element Indexes
It was noted above that you need to pre-assign element indexes to each committed treatment. That is, you need to determine the zero-based row index for the element in the raw input file on which the committed treatment is to be placed.
This requires some pre-processing on your part, and you may wonder why Cassandra does not do this work for you? The reason for this approach is that Cassandra is domain agnostic. Cassandra does not have awareness of the columns in your raw data that map to identifier columns in your committed treatments.
For example, for a Bridge Management System, your committed treatments may have identifier columns such as ‘bridge_id’ and ‘element_id’ whereas for a Road Network System, you are likely to have identifier columns such as ‘road_id’, ‘start_m’, ‘end_m’ and ‘lane’. Since Cassandra does not know which columns in your raw data map to which columns in your committed treatments (e.g. yellow columns in the figure above), we need your help to do this pre-processing using the knowledge of your Domain Model.
A tool is provided in Cassandra to help you look up the element indexes to which your committed treatments apply. This tool can be found under the Tools menu. You can use this tool to match any secondary data set to your model input set. The results of this index lookup is then exported to a file that you can pick the name and location of.
To apply this tool for indexing of elements on your committed treatment set, you need to specify your committed treatments file as the ‘Secondary File’ when using this tool. Specify a new name for the file that you export. This new file will then be identical to your committed treatments file, but with the element indexes added. Finally, you should specify this new file as your final committed treatment set to use in your model.